Abstract
This study presents a targeted model editing analysis focused on the latest large language model, Llama-3. We explore the efficacy of popular model editing techniques- ROME, MEMIT, and EMMET, which are designed for precise layer interventions. We identify the most effective layers for targeted edits through an evaluation that encompasses up to 4096 edits across three distinct strategies: sequential editing, batch editing, and a hybrid approach we call as sequential-batch editing. Our findings indicate that increasing edit batch-sizes may degrade model performance more significantly than using smaller edit batches sequentially for equal number of edits. With this, we argue that sequential model editing is an important component for scaling model editing methods and future research should focus on methods that combine both batched and sequential editing. This observation suggests a potential limitation in current model editing methods which push towards bigger edit batch sizes, and we hope it paves way for future investigations into optimizing batch sizes and model editing performance.
Introduction
In the rapidly evolving field of artificial intelligence, keeping large language models (LLMs) up-to-date with the latest information is a major challenge. Traditional retraining methods are time-consuming and resource-intensive. Model editing, an alternative approach, allows for modifying stored facts and correcting inaccuracies without extensive retraining. Techniques like ROME, MEMIT, and EMMET optimize the preservation-memorization (PM) objective and can be applied to any transformer-based LLMs. This work presents a step-by-step guide for using these model editing methods on the new Llama-3 model. It explores singular edits, batched edits, and sequential-batched edits, comparing their performance. Findings suggest that sequential-batched editing with a batch size of 1024 provides optimal scaling performance and approaches the continual learning paradigm. This study establishes benchmarks for future research and outlines the decision-making process for model editing.
Background
Preservation-Memorization Objective
Gupta et al. (2024b) demonstrate that both ROME and MEMIT optimize the same objective function, known as the preservation-memorization objective. This objective comprises two parts: a preservation term and a memorization term. ROME uses an equality-constrained optimization for memorization:
\( \text{s.t.} \quad \hat{W} k_e = v_e \quad \text{memorization} \)
Here, \( W \) represents the weights of the feed-forward layer to edit, \( k \) is a key-vector representing a fact, \( v_e \) is the desired output, and \( K_0 \) is a matrix of facts to preserve. The ROME solution is:
\( \Delta = (v_e - W_0 k_e) \frac{k_e^T C_0^{-1}}{k_e^T C_0^{-1} k_e} \)
MEMIT optimizes the same objectives but uses a least-squares constraint for memorization, enabling closed-form solutions for batched edits:
In this context, a fact is represented by a pair of key (\( k_e \)) and value (\( v_e \)) vectors. The MEMIT solution is:
\( \Delta = (V_E - W_0 K_E) K_E^T (\lambda C_0 + K_E K_E^T)^{-1} \)
Gupta et al. (2024b) also introduced EMMET, which allows for batched edits using an equality constraint for memorization:
\( \text{s.t.} \quad \hat{W} k_e^i = v_e^i \quad \forall i \in [1, 2, ..., E] \quad \text{memorization} \)
The EMMET solution is:
\( \Delta = (V_E - W_0 K_E) K_E^T C_0^{-1} (K_E^T C_0^{-1} K_E)^{-1} K_E^T C_0^{-1} \)
Model editing metrics
Metrics to analyze the success of model edits are drawn from standard model editing metrics (Meng et al., 2022b; Yao et al., 2023):
- Efficacy Score (ES): Measures the success of an edit within the model, determined by the percentage of cases where \( P(\text{new fact}) > P(\text{old fact}) \) for the query prompt.
- Paraphrase Score (PS): Evaluates a model’s ability to generalize after an edit, measured by the percentage where \( P(\text{new fact}) > P(\text{old fact}) \) under paraphrases of the query prompt.
- Neighborhood Score (NS): Represents the locality of model editing by measuring the impact of an edit on adjacent stored facts within the model. NS quantifies the percentage of nearby facts that remain unchanged after an edit, assessing the precision and isolation of the modifications.
- Composite Score (S): A holistic measure defined by Meng et al. (2022a), combining aspects of edit success, generalization, and locality. It is calculated as the harmonic mean of ES, PS, and NS, providing a comprehensive evaluation of the overall efficacy of model edits.
Experiments
Finding Optimal Layer for Model Editing
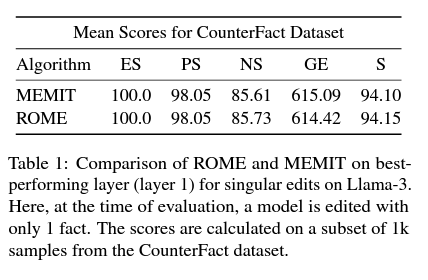
Meng et al. (2022b) found that the representation of the subject’s last token within the feed-forward networks (FFN) at intermediate layers is crucial for recalling facts in large language models (LLMs). Building on this, Meng et al. proposed treating linear layers as a key-value memory system to enhance memory recall by modifying effective hidden states. However, later work by Hase et al. (2024) showed that layers important during causal tracing did not always translate to improved model editing performance. To determine the optimal layer for model editing, 1000 non-sequential edits from the CounterFact dataset were applied to each layer of the Llama-3 model. The effectiveness of these edits was evaluated using Efficacy Score (ES), Paraphrase Score (PS), and Neighborhood Score (NS). The layer with the highest harmonic mean score across these metrics was selected as the most suitable for targeted interventions. Findings indicate that layer 1 of Llama-3 consistently outperforms other layers across numerous metrics, a result consistent with previous findings for Llama-2. This contrasts with Yao et al. (2023), who suggested that layer 5 was optimal for Llama-2 model editing. Additionally, both MEMIT and ROME show similar performance across model layers, supporting the idea that while they optimize the same objective, their differing constraints have minor effects on editing performance. MEMIT's least-square constraint allows for a closed-form solution for batched editing, as extended by Gupta et al. (2024b) with EMMET.
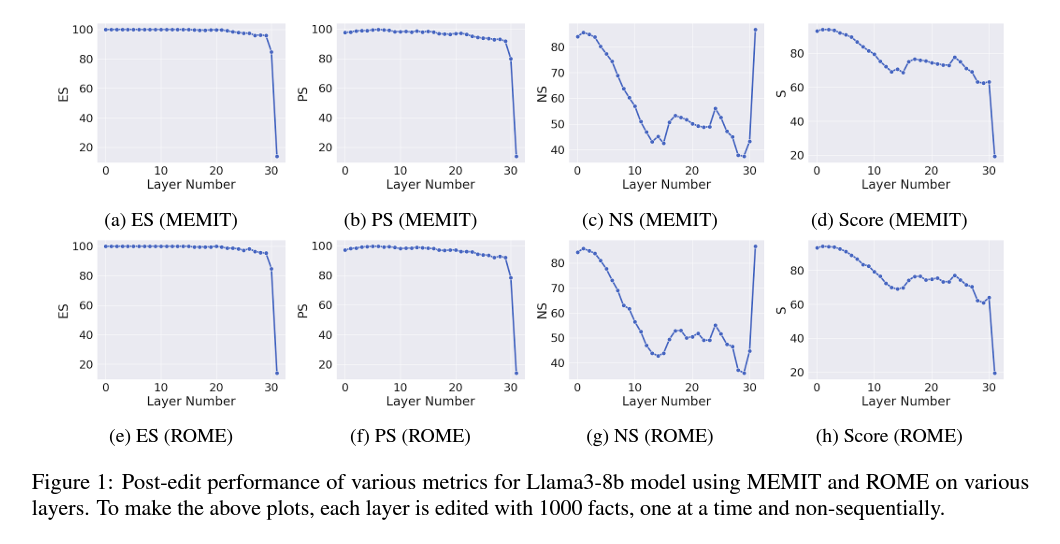
Batch Editing
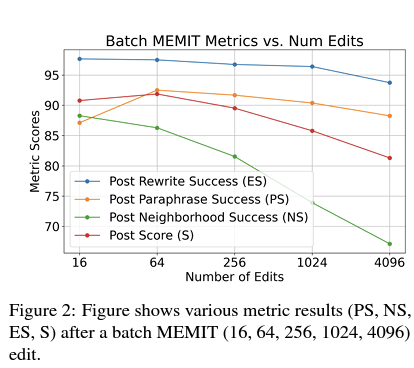
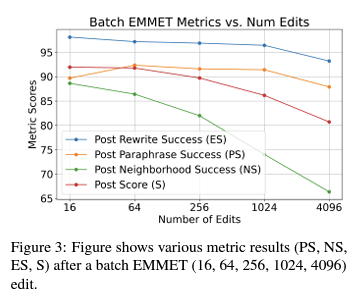
After identifying the optimal layer (layer 1) for model editing, large-scale edits were performed on Llama-3 using batched editing with MEMIT and EMMET at various batch sizes (16, 64, 256, 1024, and 4096). Gupta et al. (2024b) suggested that editing multiple layers could obscure the effectiveness of model edits, so only a single layer was edited.
Findings:
- MEMIT:
- Metrics tend to decline with larger batch sizes, particularly the Neighborhood Score (NS), indicating a significant impact on the locality of edits.
- Efficacy Score (ES) remains relatively resilient to edits.
- Paraphrase Score (PS) initially increases dramatically between batch sizes of 16 and 64, suggesting an area for further investigation.
- EMMET:
- Similar to MEMIT, metrics generally fall with larger batches, with NS being the most affected.
- Overall, both MEMIT and EMMET show similar trends due to their analogous optimization objectives.
These results highlight the need to mitigate impacts on locality when performing large-scale model edits.
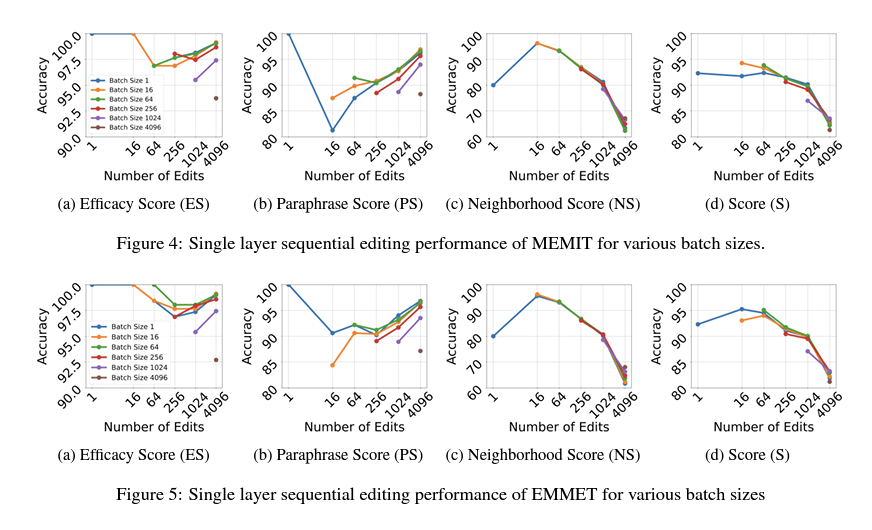
Sequential Batch Editing
Experiments show that as the batch size of edits increases, model editing performance decreases significantly, particularly for the Neighborhood Score (NS), indicating that larger batch sizes cause edits to affect other facts in the model. To address this, sequential editing, where facts are added one by one, is proposed as an alternative. Sequential-batched editing generalizes this idea by updating batches of facts sequentially, with batch sizes ranging from 1 to 4096. Sequential edits with smaller batches outperform larger batch sizes in preserving model performance, with the worst performance observed for a batch size of 4096. Sequential edits better maintain the locality of edits, reducing the impact on adjacent stored facts. Both MEMIT and EMMET show similar trends, with an optimal batch size of 1024 providing the best balance. Increasing the batch size beyond this point leads to diminishing returns and greater model degradation, suggesting that sequential-batched editing with smaller batches is more effective for enhancing model accuracy and efficiency.
Conclusion
Our study examines several model editing techniques in the context of the newly released Llama3 model. Contrary to previous belief, our experiments show that earlier layers may be more optimal intervention points, and that smaller, frequent sequential batch size edits have a superior performance in comparison to larger batch sizes. Future work will include experiments on multi-layer intervention for edits, as well as experiments against other popular models and algorithms, including methods that are hyper-network based.