Abstract
Recent work on model editing using Rank-One Model Editing (ROME), a popular model editing method, has shown that there are certain facts that the algorithm is unable to edit without breaking the model. Such edits have previously been called disabling edits (Gupta et al., 2024). These disabling edits cause immediate model collapse and limits the use of ROME for sequential editing. In this paper, we make two main contributions. Firstly, we show that model collapse with ROME only happens when making edits using the CounterFact dataset (Meng et al., 2022a) and does not happen when using the zsRE dataset (Levy et al., 2017). Secondly, we find that disabling edits are an artifact of the original implementation of ROME. With this paper, we provide a more stable implementation ROME, which we call r-ROME and show that we no longer observe model collapse when making large scale sequential edits with ROME.
Introduction
Model editing in Large Language Models is essential as the knowledge they contain becomes outdated. This paper focuses on ROME, a parameter-modifying model editing method, highlighting the challenges of editing multiple facts and the occurrence of "disabling edits" that lead to model collapse during sequential editing.
Background
ROME is explored in-depth as a model editing approach that modifies model parameters. It is part of the "locate-and-edit" category, which involves identifying and modifying the weights of specific layers corresponding to stored knowledge. Disabling edits have caused model collapses in the past, an issue this paper aims to resolve.
Experiments
The experiments begin with identifying disabling edits using metrics such as generation entropy and the norm of the matrix update. The paper investigates why these disabling edits occur with ROME, particularly when using the CounterFact dataset, and not with the zsRE dataset. The re-implementation of ROME, named r-ROME, is introduced, showing no model collapse when making large-scale sequential edits.
Metrics to Identify Disabling Edits
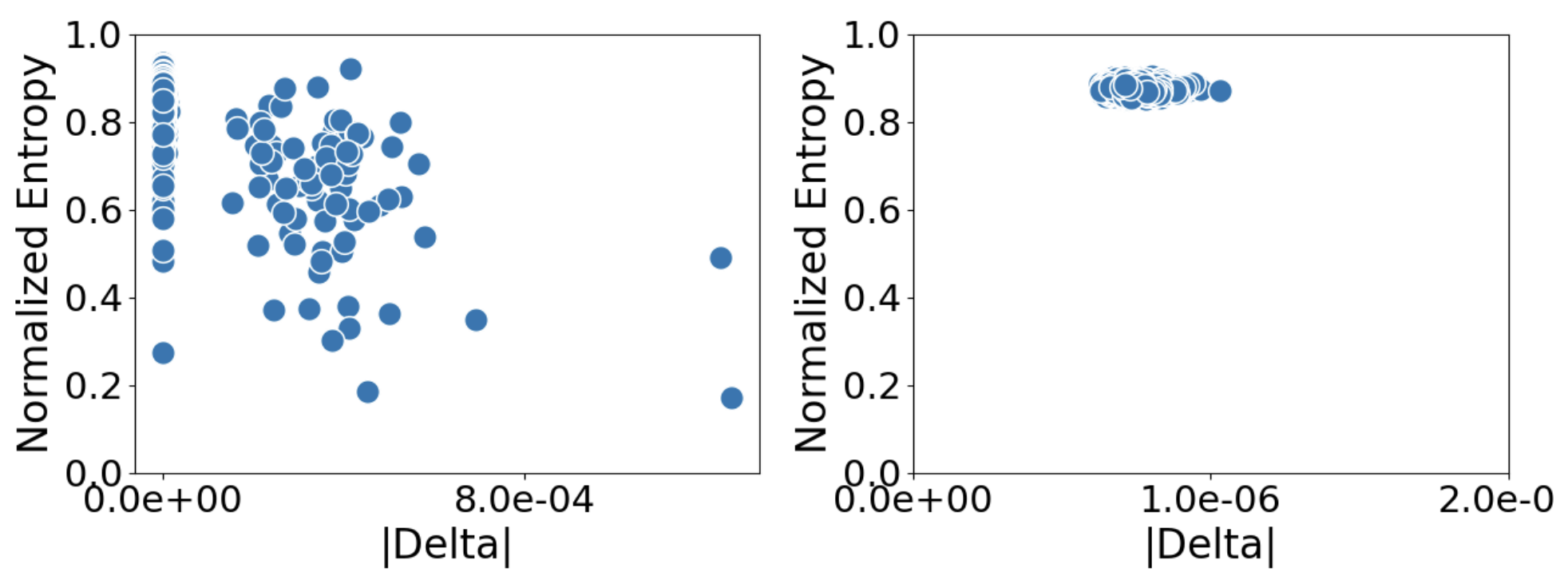
The researchers introduced two metrics to spot disabling edits: normalized matrix update norm (|Δ|) and generation entropy. Disabling edits were characterized by an unusually large update norm, and generation entropy was employed to identify when models repetitively generated text, indicating a collapse. The study observed that disabling edits were specific to the CounterFact dataset edits and not present with the zsRE dataset.
Searching for Disabling Edits
A series of large-scale singular edits using ROME on GPT2-XL and GPT-J models was conducted with two datasets, CounterFact and zsRE. The results confirmed that disabling edits appeared only in the CounterFact dataset. It was surmised that the disabling edits' presence might be due to the nature of the facts in the dataset, the style of prompts used, or the one-word nature of the CounterFact edits.
Fixing Disabling Edits
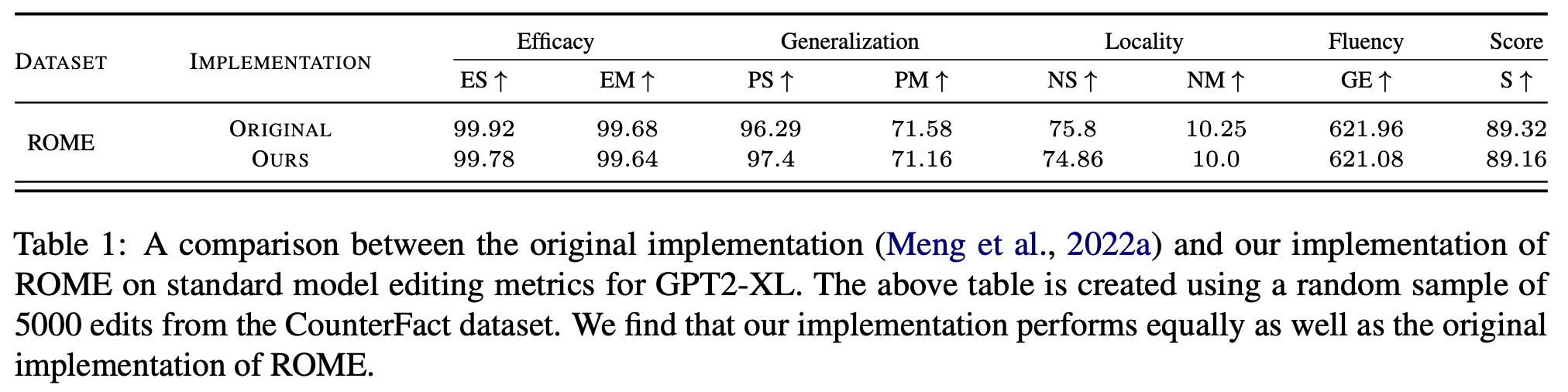
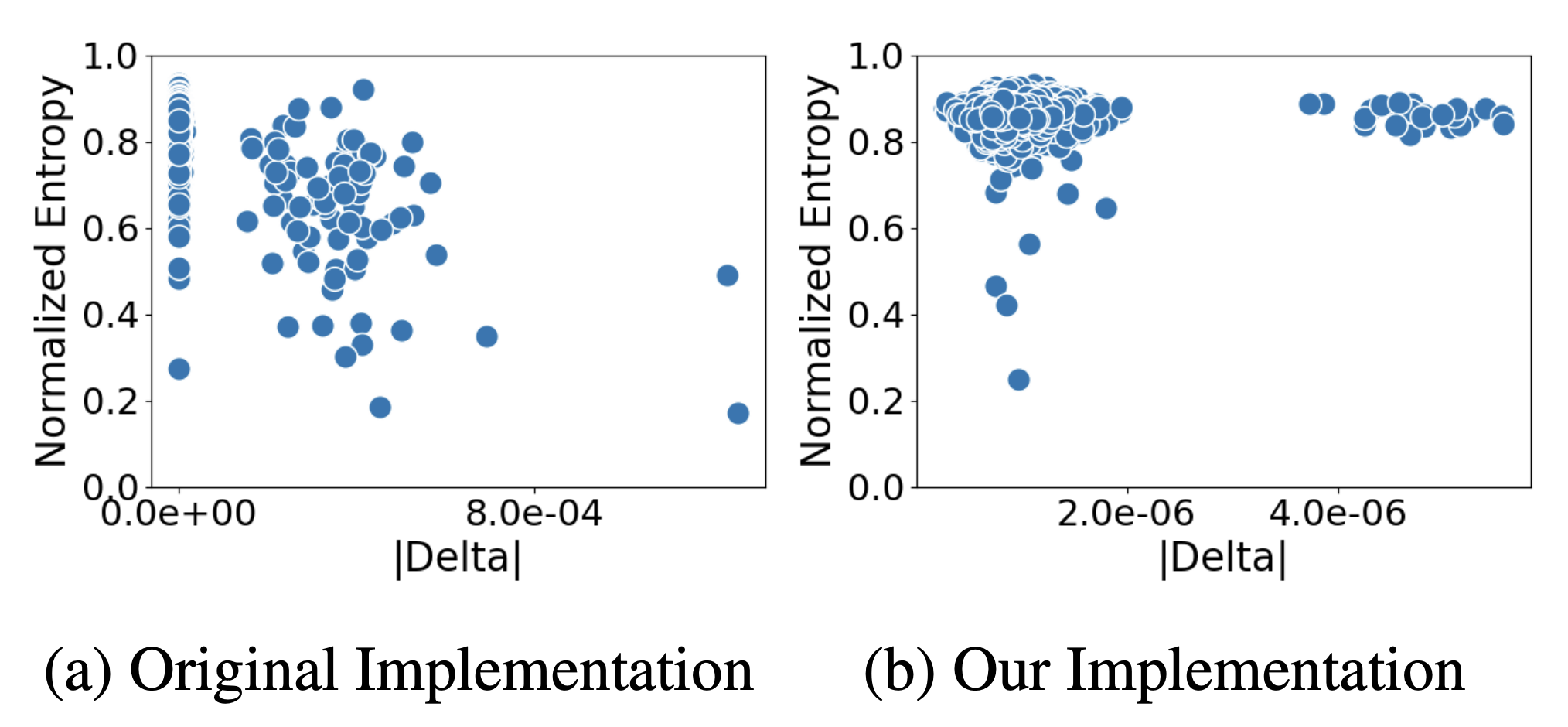
The research team re-implemented ROME, creating r-ROME, and found that it did not result in disabling edits. The new implementation's updates were smaller in norm and did not lead to the previously observed model collapse. The performance of r-ROME matched the original on standard model editing metrics while eliminating the risk of disabling edits.
Sequential Editing with ROME
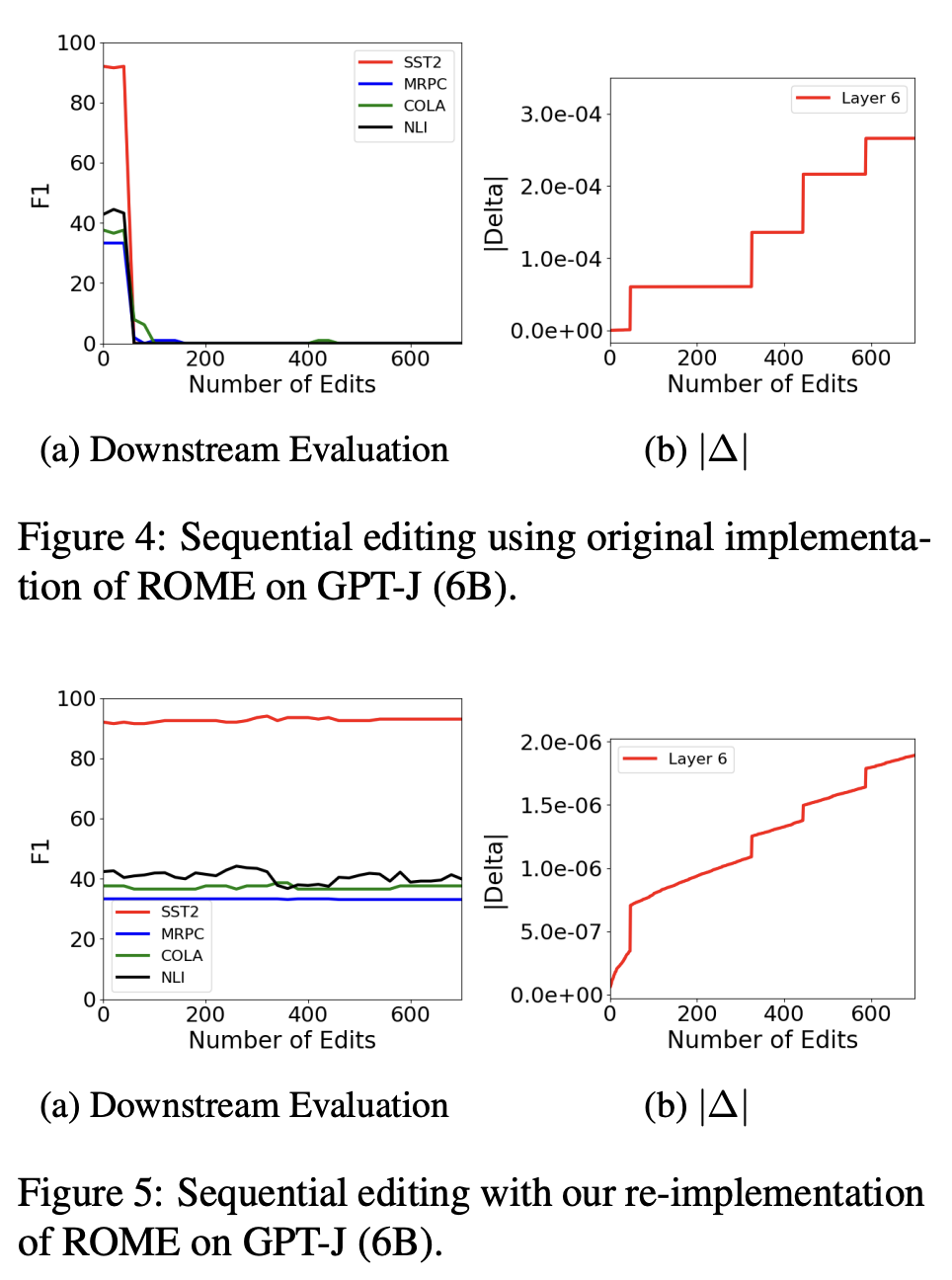
The paper presents a final test of the re-implementation by performing sequential editing. The original ROME showed a sudden model collapse after encountering a disabling edit, but the new r-ROME maintained stable downstream performance and general abilities throughout sequential edits, thus validating the new implementation.
Conclusion
The research concludes that the original implementation of ROME led to unstable model edits and model collapse. The new implementation, r-ROME, avoids this and enables stable, scalable model edits. This allows for sequential editing without performance loss, marking a significant advancement in model editing techniques.